


生成AIを活用した用語抽出
目次[非表示]
用語集とは
用語集は、翻訳において専門用語や固有名詞といった単語やフレーズを訳文言語において決まった訳語に翻訳するために不可欠な資料です(用語集の重要性についてはこちらの記事を参照)。また、機械翻訳においても対訳用語集を用いることで、指定した訳語を出力させることができるため翻訳精度の向上に有用な資料です。
基本的な用語集の作り方は至ってシンプルです。まずは対象となる文書から用語を抽出し、適切な訳語を対応させる。これだけです。ただし、対象となる文書が膨大にあり、さらに同じく膨大な量の過去の翻訳された文書から対応する訳語を見つけるとなるとどうでしょう。途方もない時間と労力が必要になってしまいます。
この作業を自動化すべく、ツールを用いた用語抽出の方法も考案されましたが、従来の方法では大量の候補から精度の高い用語を抽出するのは非常に困難で、特に対訳での抽出はとても実用レベルとは言えませんでした。しかし、生成AIの導入により、このプロセスが効率的かつ正確に行えるようになっています。
従来の課題
これまでの用語抽出ツールでは、形態素解析などの技術を応用し大量の文書から出現頻度の高い用語を自動的に抽出する方法を用いていました。この方法では、大量の文書から用語の候補を自動的に抽出することはできましたが、抽出結果には多くのノイズ(不要な用語候補)が含まれてしまい、また、対訳用語の抽出にも対応できないため、結局は人の目による選別に多大な時間と労力を要していました。
生成AIによる新たなアプローチ
そこで、昨今話題の生成AIを活用することで、指定した分野の用語を高精度に抽出することが可能になりました。生成AIは、プロンプトによって抽出する用語の細かい指示にも柔軟に対応できるため、必要な用語だけを効率よく取り出すことができます。さらに、対訳用語の抽出も可能となり、対訳での用語抽出も可能となりました。
工夫したポイント:ファインチューニングと対訳抽出の分離
ただし、生成AIも万能ではありません。プロンプトを細かく調整したとしても、ノイズが混じったり必要な用語を抽出できなかったりといったことが一定の割合で発生しました。そこで、精度をより向上させるために更なる工夫を凝らしました。
まず、原文での用語抽出と訳文を対応させるプロセスを別タスクとして行いました。また、それぞれに対してAIモデルをファインチューニングすることで、各タスクの精度を向上させました。ファインチューニングとは、生成AIに特定のデータを学習させて、処理精度をさらに高めるプロセスです。例えば、特定の文書に含まれる用語のパターンを学ばせることで、不要な用語候補を減らし、目的に適した候補のみを選定できるようになりました。対訳抽出でも同様に、訳語が適切に対応しているデータを用いて学習を行い、精度を向上させています。
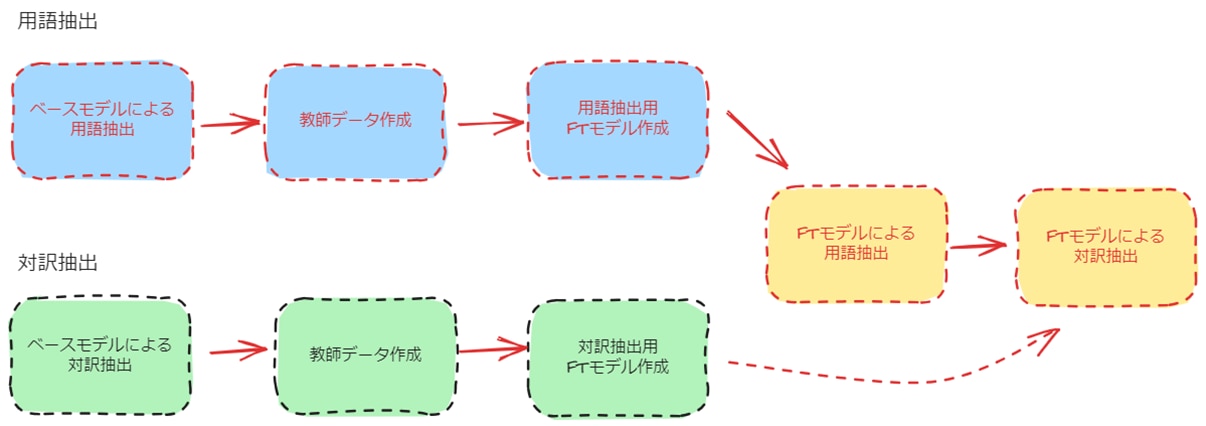
生成AIを用いた用語抽出プロセス
実際の効果と今後の可能性
ファインチューニングを施した生成AIを活用した結果、従来の方法では発生していたノイズが大幅に減少し、厳選された用語のみを抽出できるようになりました。また、対訳データの抽出もスムーズに行え、用語集としての一貫性が増しています。今後は、さらに多くのサンプルデータで検証を行い、生成AIによる用語抽出の可能性をさらに引き出していく予定です。
生成AIによる用語抽出は、文書量の多さに悩む多くの企業にとって、新たな解決策となり得るでしょう。これまで断念していた用語集の構築も、この技術を活用することで現実のものとなります。ぜひ一度、生成AIを活用した用語抽出に挑戦し、効率的な業務改善を実現してみませんか?
川村インターナショナルのサービス
川村インターナショナルでは、生成AIを活用した用語集抽出のみならず、「みんなの自動翻訳@KI(商用版)」のほか、さまざまなAI翻訳を活用したサービスも多く揃えており、セキュリティ要件、目的、分野、想定ユーザー層の要件に応じた幅広いご提案が可能です。ぜひお気軽にご相談ください。
関連記事






