自動翻訳を活用して翻訳生産性をもっと向上させたい!
今後の自動翻訳の注目ポイントとは?
ニューラル自動翻訳の登場から、機械翻訳の精度は見違えるほど向上しました。一方で、対象となる分野によってはまだまだ納得のいく品質が出ていないケースが発生しています。
ビジネスのさまざまな場面で、幅広く機械翻訳を活用するには、より多くの分野で翻訳の出力結果を向上させる必要があります。
当社は生産性向上という観点から「翻訳バンク」、「ドメインアダプテーション」、および「インタラクティブ学習」の3つに注目しています。
対訳データは多ければ多いほどよい
機械翻訳の研究者、開発者、そして当社のような民間の機械翻訳サービスプロバイダーの中で共通の認識になっているのは、「教師データである対訳データ(コーパス)は多ければ多いほどよい」ということです。(※執筆時2018年時点での情報です)
検索サービスを提供しているGoogleやMicrosoft、Baiduや、ECの巨人Amazonといった海外の大企業は、インターネット上の翻訳を効率よく収集・活用しています。
日本の機械翻訳もこうしたデータをうまく活用すべきです。そこで現在当社が注目しているのが、国立研究開発法人情報通信研究機構が2017年9月に開始した「翻訳バンク」構想です(http://h-bank.nict.go.jp/about.html)。
中央官庁、地方自治体以外の民間企業からも対訳データ(コーパス)を収集して、機械翻訳の精度向上につなげようという試みです。この枠組みが広く浸透させることが出来れば、近い将来に非常に精度の高い、メイドインジャパンの機械翻訳が民間でも活用できるようになるかもしれません。
分野に特化したカスタマイズは可能
GoogleやMicrosoft、DeepLなどの機械翻訳エンジンは、対訳データ(コーパス)を持っていなくても幅広いコンテンツに対応できるのが魅力です。
一方で、当社のような翻訳会社が対応するコンテンツには、特許や医薬品・医療機器などの申請文書のほか、商材によっては専門性が要求される製品のマニュアルやWebサイトなど、汎用的な機械翻訳エンジンが苦手とするコンテンツが多く含まれます。
こうしたコンテンツに対応できる専門特化型の機械翻訳を構築する処理を「ドメインアダプテーション」と言います。”In-domain adaptation” キーワードで検索すると多くの論文がヒットすることからもわかる通り、開発者の中でも注目されている技術です。
当社でも過去に掲載した検証記事「分野・企業に特化した機械翻訳エンジンは作れるのか」でもはっきりとした結果が出ているように、かなりの精度向上が見込めます。
インタラクティブに記録→学習→反映できる自動翻訳エンジン
すでに述べたように、機械翻訳は対訳データ(コーパス)を増やすことができれば精度向上が見込めます。実際は機械学習をさせる際には膨大なITリソースを消費するため、少量で都度実行するより一定量のデータがたまった段階で機械学習を実行させるのが効率的です。
一方で実際のエンドユーザー側では、都度機械学習をしてほしいと期待しています。そこでそうした期待に応えるべく、活用されているのがインタラクティブ学習です。これはGoogleのサジェスト機能に似た処理で、ユーザーが入力した単語や文章の履歴を元に、入力途中でも変換結果を予測して、入力を補助します。
精度が向上したニューラルネット自動翻訳とインタラクティブ学習を組み合わせることで、言語の組み合わせによっては、人手の翻訳に比べて5倍の生産性が達成できたケースもあるという検証結果(他社調べ)もあるくらいです。
インタラクティブ学習は、どちらかというと人が翻訳作業をする場合のみでのメリットですが、機械翻訳だけでは、まだまだそのまま使えないことも多いため、ニューラル自動翻訳の結果を後編集するような場合においては、今後は欠かせない技術になると思います。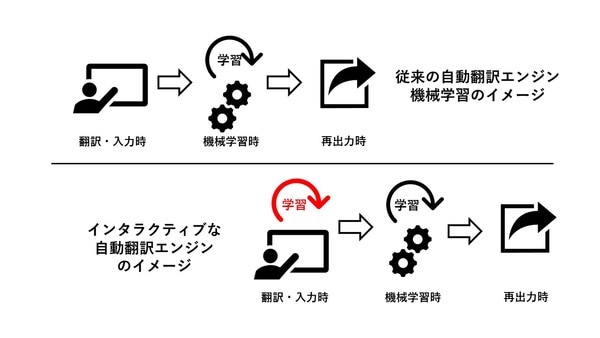
まだまだ開発途上ですが、こうした技術や枠組みをうまく組み合わせて、言葉の壁を少しでも取り除くことが出来るようにしたいですね。
川村インターナショナルのサービス
川村インターナショナルでは、「自社に最適な機械翻訳エンジンがわからない!」というお悩みにお応えします。本記事でご紹介した「みんなの自動翻訳@KI(商用版)」のほか、さまざまな機械翻訳ソリューションを多く揃えており、セキュリティ要件、目的、分野、想定ユーザー層の要件に応じた幅広いご提案が可能です。
機械翻訳の活用をご検討されている方は、ぜひお気軽に資料請求ください。
関連記事