


【検証】分野・企業に特化した機械翻訳エンジンは作れるのか
【検証】分野・企業に合わせてカスタマイズした機械翻訳エンジンは作れるのか
2017年は機械翻訳エンジンの精度向上が特に注目された一年でした。11月に開催された日本翻訳連盟(JTF)という翻訳業界団体のイベントでも、機械翻訳技術は注目を集めました。関連するセッションは長蛇の列ができ、参加することができなかった聴講者がいたほどでした。
当社でも機械翻訳やポストエディットの引き合いは急増し、翻訳業界新時代の幕開けを感じた一年でした。
今回は、機械翻訳サービスの営業時にお客様からよくお問い合わせをいただく項目から、「分野・企業に特化した機械翻訳エンジン」をテーマに、検証を行った結果を報告したいと思います。
まず、一般的に、企業が機械翻訳を選択する際に、判断のポイントになるのは大きく3つです。
1. 人手の翻訳よりも早く、安く処理ができるかどうか
用途に応じた品質・コスト・納期(QCD)のバランスが大切なのは言うまでもありません。
一般的には、社内文書か公開文書かという用途や、専門性の有無、短縮できる時間的メリットなどを考慮し、機械翻訳を活用した場合とそうでない場合との費用を比較検討しています。しかしそこでは、「使える!」と感じる一定の品質レベルが存在します。
従来の機械翻訳では、この「壁」がなかなか破れませんでした。ところがGoogle NMTやDeepLなどのニューラル翻訳が一定水準の精度を超えたことで、ようやく前向きに機械翻訳の活用を検討する企業ユーザーが増えてきました。
2. 情報セキュリティに関連したポイント
機械翻訳実行時に、原文情報が収集されるのか、どこに保存されるのか、あるいは他社と共有されるのか。これは企業にとってはとても重要な判断材料になります。
Google翻訳のPremium Editionでは下記の通り他社との情報共有がされないなど明確な言及がありますが、一時的とはいえデータがどこに保存されるのかが分からないなどの点を不安視される声も耳にします。
(参考)https://cloud.google.com/translate/faq?hl=ja
それでも、大企業では自社のセキュリティポリシーとの兼ね合いで、Google翻訳を採用できないケースが依然として存在します。同様に、Microsoft Translator Hubもクラウドという部類にカテゴライズされ、選択肢から消えるケースがあります。
しかし、GoogleやMicrosoftの強みは機械翻訳の元となる汎用データを大量に保有している、ということです。これらのサービスを除外する企業は、自社で保有している対訳データだけでは一定レベル以上の機械翻訳結果を出すことは、難しいというジレンマと向き合うことになるでしょう。
3. 用語、分野、企業固有のコンテンツに特化したカスタマイズ
1も2もクリアできた場合、たいていのお客様は、用語が毎回異なって出力されることに不満を感じたり、独自のルール、専門性を補完できないなどの課題を抱えたりすることになります。
用語に関しては、機械翻訳処理の前後で検索置換を行うフェーズを入れることで、ある程度自動化できるエンジンが出てきています。では、分野専門性はどのように補完ができるでしょうか。
こうした課題を解決するため、あるアプローチが存在します。
In-domain adaptation という可能性
ここで、In-domain adaptation というカスタマイズ処理を紹介します。
これは、一定規模の汎用対訳データ(最低でも 3000万文程度)と、一定量以上の自社、あるいは特定分野の対訳データを合わせてトレーニングすることで、その分野に特化したエンジンを構築するカスタマイズ処理です。
<検証>
この記事を作成している2017年12月25日現在、GoogleやMicrosoftも自社で保有するデータを活用してNMTエンジンの性能を向上させることはできません。
そこで、この機能を備えたGlobaleseというエンジンを活用して、検証をしてみました。
(注:Microsoft Translator Hubでは自社のデータを活用してSMTエンジンの性能を向上させることは可能です)
検証に使用したソフトウェアおよび情報資産は以下の通り
- NMT エンジン: Globalese 3.0
- 言語方向: 英語→日本語
- 分野: IT
- 汎用対訳データ量: 約4000万文
- 分野特化した対訳データ量: 約600万文
これらの情報資産を活用し、In domain-adaptationを実施して、出力結果を検証しました。
検証は、In domain-adaptationを実施する前のエンジンと、実施した後のエンジンの出力結果を人手によって品質評価しており、以下のレベルで評価してもらいました。
評価基準は以下の通り
- 精度が向上したため人手による修正が不要なレベル
- 精度が変わらないが人手による修正は不要なレベル
- 精度が向上したが、人手による修正が必要なレベル
- 精度が悪化し、人手による再翻訳が必要なレベル
<結果>
7割の訳文で精度が向上!
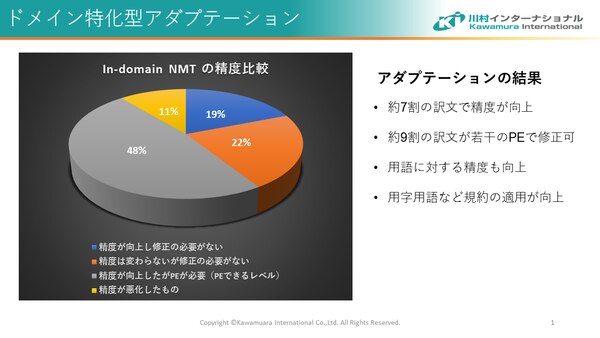
上記のグラフの通り、カスタマイズ前と比べて約7割の訳文の質が向上しました。特筆すべきポイントは最初から再翻訳をしなければならない出力は11%しかなかった、ということです。
また、この検証実験では定義された用語が正しく使用される率が36%向上し、その中には「書き換え」→「書換え」などの表記ルールへの準拠が改善したケースも含まれています。
In-domain adaptationは有効。今後の各社の対応に期待。
今回は、分野特化した対訳データ量も約600万文あり、それなりの量の対訳データを活用できたためうまくいったという可能性は否めません。
ただし、欧州語⇔英語では汎用データが一定以上存在すれば、分野特化した対訳データ量は10万文程度でも大きく改善がみられた、というケースも報告されています。
10万文と言えば100万ワード程度の対訳データになります。常に翻訳を外注している大企業であれば、不可能なボリュームではありません。
In-domain adaptation はよい効果を生むことが予測されます。
今後は、Google NMTやMicrosoft Translator Hubなどでも自社データを活用したカスタマイズができるようになるでしょう。そういう時代はそう遠くないと確信しています。そうなったとき、企業は自社で機械翻訳エンジンを構築して、メリットを享受できるでしょうか。
その時に自社で機械翻訳エンジンを活用できていなければ、他社と比較して市場投入が遅れたり、価格競争力が低下したりする可能性があります。市場での競争力を失う前に、機械翻訳に一度向き合ってみませんか。次の一手が見えてくるはずです。
アダプテーション可能な国産ニューラル翻訳エンジン「みんなの自動翻訳@KI」や、「Globalese」に関するご不明点など、お気軽に弊社までお問い合わせください。
関連記事






