
CATツールで使える正規表現・第4回
この連載では、翻訳の現場で役に立つ正規表現を取り上げながら、memoQやSDL Trados StudioのようなCATツール※で利用できる正規表現について解説しています
※ CATツールとは、翻訳支援(Computer Assisted Translation)ツールの略称で、翻訳メモリや用語集を使って翻訳業務を効率化するためのツールを指します
前回の記事では、「文字リストの中のいずれか1文字」を表す文字クラスを紹介しました。今回は、文字クラスを使って、ひらがな1文字やカタカナ1文字にマッチする正規表現を作ります。

文字の順序
前回の記事で見たように、文字クラスでは[A-Z]というように文字の範囲を指定できます。考えてみれば、「この文字からあの文字まで」という形で範囲を指定するには、文字の順序が定義されていなければなりません。
大文字アルファベットが、最初が「A」、次が「B」、最後が「Z」というようにアルファベット順に並んでいてこそ、「AからZまでのいずれか1文字」が「大文字アルファベット1文字」と一致します。
では、ひらがなやカタカナはどんな順序で並んでいるのでしょう。五十音順だとしたら、「っ」などの小書き文字や「ガ」などの濁音・半濁音はどこに並ぶでしょう。
文字の番号
現在のコンピューターで一般的に使われているUnicodeでは、アルファベットや漢字から各種記号や絵文字、さらには古代の楔形文字やヒエログリフにいたるまで、ありとあらゆる文字に番号が振られています。
このように文字に振られた番号を「コードポイント(code point)」といいます。文字クラスで文字の範囲を指定する場合、文字はUnicodeのコードポイント順に並んでいるとみなされます。
では、大文字アルファベットのコードポイントを確認してみましょう。Windowsでは「文字コード表」というアプリケーションで調べることができます。
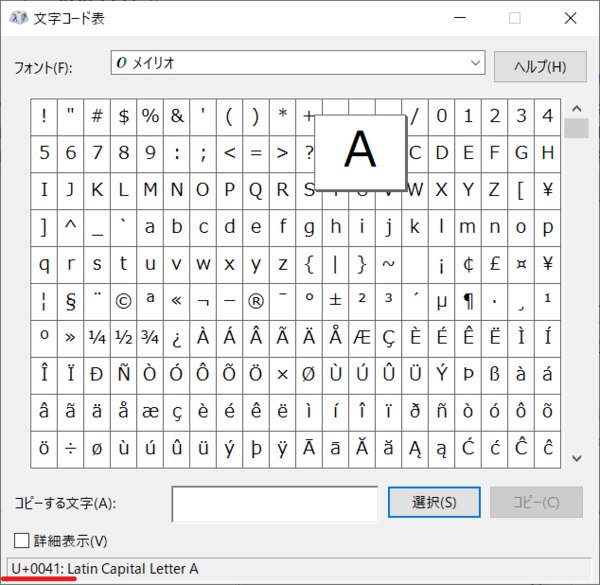
「A」のコードポイントはU+0041となっていますが、これは「A」が41番目の文字であることを表します。
そのあと、「B」はU+0042、「C」はU+0043とアルファベット順に並び、「Z」はU+005Aとなっています。つまり、「Z」は5A番目の文字ですが、「5A番目」とはなんでしょう。
実は、これらのコードポイントは16進数*で表記されています。コンピューターの内部では数字が2進数で表現されているのですが、2進数を4桁ずつまとめると16進数になるので、16進数は2進数を人間にわかりやすく表現する方法として都合がよいのです。
16進数では、0から15までが1桁で、16から2桁になります。10から15までを1桁で表すため、それぞれAからFと表記します。Fの次の数は、1桁上がって10となります。したがって、16進数の10は10進数の16です。
「A」の41も、16進数なので、四十一ではありません。10進数では65になります。「Z」の5Aは、10進数では90です。
*16進数 参照:16進数(16進法)とは - IT用語辞典 e-Words
ひらがなとカタカナ
次に、ひらがなのコードポイントを調べてみましょう。コードポイント順で最初のひらがなはU+3041の「ぁ」(小さい「あ」)です。そのあと、「あ」「ぃ」「い」・・・「か」「が」「き」「ぎ」・・・と続き、U+3093の「ん」の後に、U+3094の「ゔ」やU+309Dの「ゝ」(繰り返しを表す記号)などがあります。
そのため、正規表現で[あ-ん]としてしまうと、「ぁ」「ゔ」「ゝ」などが範囲から外れてしまいます。これらの文字を使う機会は少ないので、たいていの場合は[あ-ん]でも十分ですが、固有名詞などで範囲外の文字を使う場合には、その文字を文字リストに追加して[ぁ-ゔゝゞ]などとします。
カタカナも同様に、U+30A1の「ァ」から始まり、U+30F3の「ン」の後にU+30F4の「ヴ」やU+30FCの「―」(長音記号)などがあります。カタカナの場合は、「ァ」や「―」を頻繁に使うので、[ア-ン]では実用上問題があります。少なくとも[ァ-ンー]、「ヴ」を含めるなら[ァ-ヴー]とします。
スペースか中黒か
カタカナ1文字を表す正規表現がわかったところで、実用的な例をあげましょう。
「パーソナルコンピューター」のように、外国語で2つ以上の単語からなる言葉をカタカナで表記するとき、「パーソナル コンピューター」や「パーソナル・コンピューター」のように、単語の区切りを半角スペース「 」や中黒「・」で表すことがあります。
このようなカタカナ語の表記は、一まとまりの文章の中では統一されていないと読みにくいので、産業翻訳では多くの場合、表記ルールが定められています。このルールに違反した表記を、正規表現で検出してみましょう。
まず、カタカナ語が中黒で区切られているパターンを検索します。
カタカナ1文字を[ァ-ンー]とすると、カタカナが1つ以上連続する文字列は[ァ-ンー]+となります。したがって、カタカナ語があって中黒があってカタカナ語というパターンは[ァ-ンー]+・[ァ-ンー]+で検索できます。
これでもよいのですが、中黒が複数ある場合も検索できるようにしてみましょう。まずカタカナ語があって、そのあと「中黒+カタカナ語」が1回以上と考えると、中黒で区切られているカタカナ語にマッチする正規表現は[ァ-ンー]+(・[ァ-ンー]+)+となります。
半角スペースで区切られているカタカナ語を検索するなら、先ほどの正規表現で中黒を半角スペースに変えて[ァ-ンー]+( [ァ-ンー]+)+となります。
今回のまとめと次回の予告
今回は、文字クラスの範囲指定について詳しく解説し、ひらがなとカタカナを検索するための正規表現を作りました。次回は、引き続き範囲指定を使って、全角文字や半角文字を検索します。
|
前回までの記事はこちら
|
川村インターナショナルの翻訳サービス
川村インターナショナルでは、AIやMTの活用、プロセスの自動化やデジタル化による翻訳業務効率化ソリューションをご提案します。翻訳支援ツールの導入を検討している、自社の翻訳資産を活用して機械翻訳エンジンをカスタマイズしたい、など翻訳業務の効率化をご検討中の方は、ぜひお気軽にお問い合わせください。
また、CATツールで使える正規表現のほか、川村インターナショナルでは翻訳を効率的に行う秘訣のブログ記事を公開しています。memoQや、XTMなどの翻訳作業を効率化するCATツールや、校正ツールのご紹介など役に立つTIPSを集めた人気ブログ9記事をまとめました。用語集の作り方から、レイアウトまで効率化につながる秘訣を紹介しています。ぜひご覧ください。





%E3%81%AE%E9%87%8D%E8%A6%81%E6%80%A7%E3%81%A8%E3%81%AF.png?width=900&height=600&name=%E7%BF%BB%E8%A8%B3%E3%81%97%E3%81%9F%E3%81%82%E3%81%A8%E3%81%8C%E5%A4%A7%E4%BA%8B!%E3%83%AC%E3%82%A4%E3%82%A2%E3%82%A6%E3%83%88%E8%AA%BF%E6%95%B4(DTP)%E3%81%AE%E9%87%8D%E8%A6%81%E6%80%A7%E3%81%A8%E3%81%AF.png)

