みなさん、用語集は活用していますか?
用語集は様々な目的で作成されますが、たとえばそのうちの一つに、翻訳作業があります。用語集は翻訳の品質を左右する重要な構成要素です。ある言語から別の言語に翻訳する際に、同一のものを別の名称で書き換えていては、文書の整合性もおかしくなりますし、それによって論理性も破綻します。
では、用語集がないとどのような問題が発生するのでしょう。そして、用語集の利点とは何でしょうか。
企業で翻訳に携われる方々にとって「用語集」は非常に関心の高いテーマです。こうしたニーズに応えるべく「用語集の利活用」をテーマにして連載記事をお届けすることになりました。今回はその第ニ弾です。
第一弾は、こちらからお読みいただけます。

用語集作成ツールは実際に使えるの?
ツールA:優れた機能もあるが日本語の処理に難あり
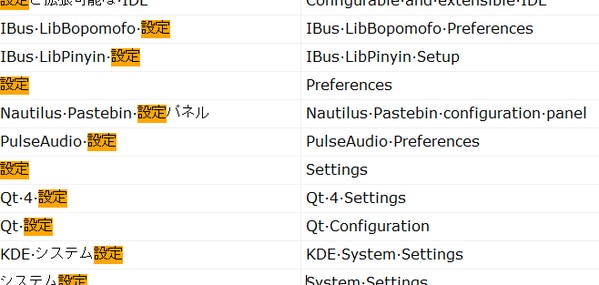
ツールB:日本語の扱いも訳語の取得も不十分
ツールBについても、既定の設定で用語集を作成しました。最初の5項目は以下のようになりました。
正しい訳といえるのは「設定 - preferences」しかありません。また、ツールAで見つけることのできた「設定」の訳揺れも、ツールBの結果からはわかりません。ツールBの訳語抽出機能は、少なくとも原語が日本語の場合は、実用的でないといえます。

ツールC:日本語の処理は十分、訳語の取得は今一歩
| 法令データ | Ubuntuデータ |
| 規定 | ゲーム |
| 必要 | ファイル |
| サイバーセキュリティ | クライアント |
| 施策 | 設定 |
| 法律 | カード |
| 認定 | アプリケーション |
| 主務大臣 | 表示 |
| 推進 | シンプル |
| 調査 | ツール |
| 業務 | 編集 |
この結果からわかるように、単語数の設定をしなくても、日本語の用語を適切に取得しています。また、この表にはありませんが、「その他」や「使い方」など、漢字とひらがなの混じった用語も抽出しています。
このツールではまた、ツールBと同様、各用語の訳語候補も抽出されます。ツールBで例に挙げた用語について、ツールCでは以下が訳語の候補として提案されました。
| 規定 | サイバーセキュリティ | ゲーム | 設定 |
| provision | Cybersecurity | game | Settings |
| provisions | Chief | Game | Configuration |
| games | Preferences | ||
| game type | configuration | ||
| trails | Configure | ||
| last game | settings |
おおむね正しい訳語が検出できていますが、用語集を作るためには、適切な候補を採用して不適切な候補を捨てる作業が必要です。また、まれに「平成 - Act」や「サーバー - EBU-R128」のような「誤訳」もあり、修正も必要です。これらは手作業で行う必要があります。
「設定」の訳語候補を見ると、訳文中でいくつかの訳語が使用されている可能性があることもわかります。ただし、これだけでは、実際の文章で原語と訳語が本当に対応しているのかはわかりません。「サイバーセキュリティ - Chief」のように、単にツールが誤った訳語を提案したのかもしれません。
訳語の候補が複数あるとき、訳文で複数の訳語が使われているのか、それともツールが正しい訳語と誤った訳語を提案しているのかを判定するには、原文と訳文を参照する必要があります。そのとき、ツールAのように原文と訳文を表示する機能があれば便利ですが、残念ながらツールCにはその機能がありません。
まとめ
- 原文と訳文を対にした対訳データがあるとき、自動的に原文から用語を抽出し、それに対応する訳語を提案してくれるツールがいくつか存在する。
- いずれのツールでも、日本語をうまく使えなかったり、重要な機能が欠けていたりして、すべての訳語を自動的に抽出することは不可能である。
- 訳語の入力や修正、複数候補からの訳語選択など、人手による作業は必須だが、ツールを使用することで、大幅な効率化が期待できる。
- 効率化ツールに必須の機能は、原文用語の抽出機能と、各用語が使用されている原文および訳文を表示する機能である。
次回は、用語集と合わせて検討すべき三大方針について共有します。
フィードバックフォーム
当サイトで検証してほしいこと、記事にしてほしい題材などありましたら、
下のフィードバックフォームよりお気軽にお知らせ下さい!
例えば・・・
CATツールを自社に導入したいが、どれを選べばいいか分からないのでオススメを教えてほしい。
機械翻訳と人手翻訳、どちらを選ぶべきかわからない。
翻訳会社に提案された「用語集作成」ってどんなメリットがあるの?
ご意見ご要望をお待ちしております!
下のフィードバックフォームよりお気軽にお知らせ下さい!
例えば・・・
CATツールを自社に導入したいが、どれを選べばいいか分からないのでオススメを教えてほしい。
機械翻訳と人手翻訳、どちらを選ぶべきかわからない。
翻訳会社に提案された「用語集作成」ってどんなメリットがあるの?
ご意見ご要望をお待ちしております!
新着記事一覧



