目次

はじめに:機械翻訳?自動翻訳?
Googleの機械翻訳サービス(Goolge NMT)が開始されてから、Neural(N:ニューラル)をベースにしたMachine Translation (MT:機械翻訳)=NMTという言葉が頻繁に使われるようになりました。“Machine“という単語の辞書的な意味はもちろん 「機械」です。そのため、“Machine Translation"の訳語に「機械翻訳」という日本語を充てることには全く違和感がありません。
ところが”MT”に関連したサービスを提供する事業者であれば、必ず一度は頭を悩ますことがあります。それは、「自動翻訳」と「機械翻訳」のどちらを使うのが適切なのか、ということです。
当然、「自動」と「機械」の日本語の意味は異なります。さらに「自動翻訳」という日本語に対する英語訳は本来Automatic Translationであって、Google NMTでもそのように翻訳されます。
音声翻訳の領域では頻繁に使用される「自動翻訳」という言葉
館内放送や公共交通機関での表示は、施設から利用者への単一方向のメッセージングであるため、スクリプトや音声を事前に準備をすることができます。多くの場合はプロの翻訳者(あるいは翻訳会社)が多言語化の対応をしています。
一方で、チケットの発券対応や飲食店の注文など、時には双方向のコミュニケーションが発生する場では、リアルタイムな対応が求められるため、事前に想定問答集を用意することで一定の効率化ができたとしても、完全には対応できません。そこで登場するのが自動音声翻訳です。
実は「自動翻訳」という言葉は、上記の音声の領域で多数を占めています。本記事公開時点のGoogleの検索結果でも、「自動音声翻訳」と「機械音声翻訳」の間に大きな差が見て取れます。
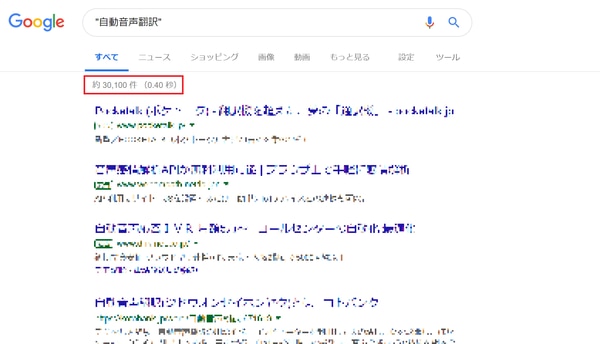
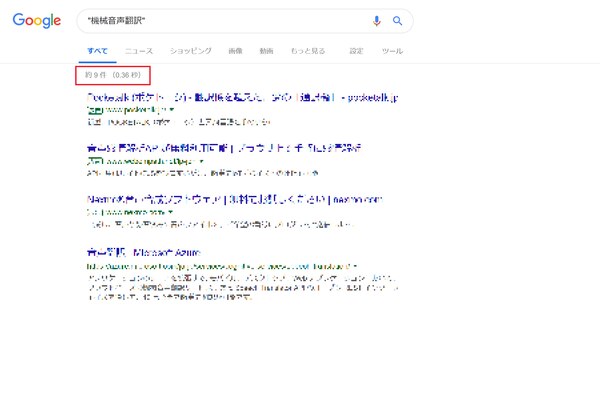
この領域では、「機械音声翻訳」よりも「自動音声翻訳」の方が単に響きがいい、という理由もあるかもしれません。音声翻訳ではそもそも音声を入出力するための端末を準備する必要があり、その端末自体が「機器」として認識されます。その「機器」と「機械」の意味的な重なりがあるため、「自動」の方がしっくりくるのかもしれません。

「機械翻訳」は音声の「自動翻訳」の一部を構成している
文書の翻訳の場合は、翻訳したい文書をブラウザに入力すれば翻訳結果が返ってきます。音声翻訳の場合は、音声から文字に変換する「音声認識」を最初に行います。次に、文字を「機械翻訳」エンジンに投入して翻訳を行います。その後に、テキストの結果を音声として出力するために「音声合成」を行います。つまり、機械翻訳の技術は、音声翻訳を実現するためのコアの技術の一部として含まれています。
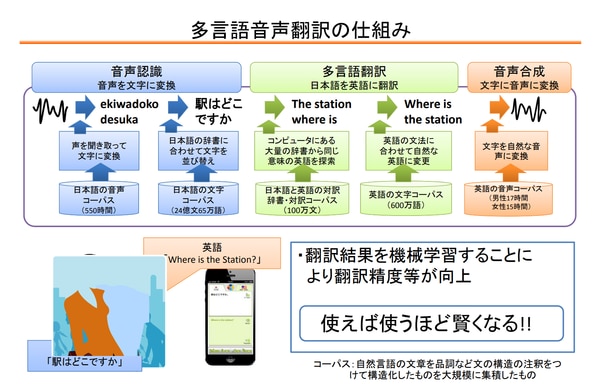
引用元:「多言語音声翻訳システムの紹介」(平成26年4月18日 総務省 情報通信国際戦略局 技術政策課 研究推進室)
音声翻訳では、機械翻訳をコア技術として出力までにかかるプロセスを自動化させることで、ユーザー側に翻訳された音声を提供することができます。つまり、音声の「自動翻訳」という言葉には、「機械翻訳」のほかに「自動化」の意味が包含されているとも言えます。そして、音声自動翻訳では、出力した音声をそのまま使うことを前提としていることが多く、人間の介入は最小限のものになっています。
文書の翻訳に「機械翻訳」が使われる理由
音声翻訳では、リアルタイム性が重視され、その場のコミュニケーションが成立することが最も重要なポイントです。
音声翻訳が必要とされるのは、対話の場です。多少間違っていても、当人同士の身振りや手ぶり、質問や確認などの行為によって相互理解を補完できるという特長もありますが、人間が修正をする行為は最小限にとどめなければ、手間がかかりすぎて対話にならないとも言えます。
一方、文字から文字への翻訳については、コミュニケーションのほかに「記録として残す」という重要な役割も持つため、ビジネスの世界では翻訳文書の配布、保管、管理も重要視されています。公開・保管されるものであるならば、それなりの品質が求められますが、現時点の「機械翻訳」の品質では人の介入を完全に排除できるほど完璧ではありません。
欧米の市場では「ポストエディット(post-editing=後編集)」という言葉が浸透しつつありますが、これは機械翻訳の出力結果を、人間が修正する行為を指します。人の介入を最小限にした(人が修正をしない)機械翻訳のことを、仮に「自動翻訳」と呼ぶとするならば、文書の翻訳ではまだまだ「機械翻訳」という表現を使うことが正しいとも言えます。

「翻訳支援」と「言語理解」の違い

おわりに:文書の翻訳の「自動翻訳」化は遠い?
文書の翻訳は思った以上に複雑なプロセスを構成しています。企業であれば、マニュアルやWebを制作する際には「Contents management System: CMS (コンテンツマネジメントシステム)」上で文書を作成したり、AdobeのDTPアプリケーション(FrameMaker、InDesign、Illustratorなど)を使用したりすることが多いと思いますが、そうした場合には、そのアプリケーションやCMSから対象の文書を抽出する必要があります。
翻訳支援ツールはそうした抽出から、翻訳後に元のファイル形式に変換しなおす機能を備えているものが多く、ドキュメントの翻訳が必要な企業にとってはとても有用です。この抽出・変換機能に加えて、過去に翻訳した箇所に類似している部分には「翻訳メモリ」を、新規の翻訳対象箇所には「機械翻訳」を適用することで、できる限り新たに翻訳する箇所を減らすということが、翻訳を発注する側の大きな関心になっています。
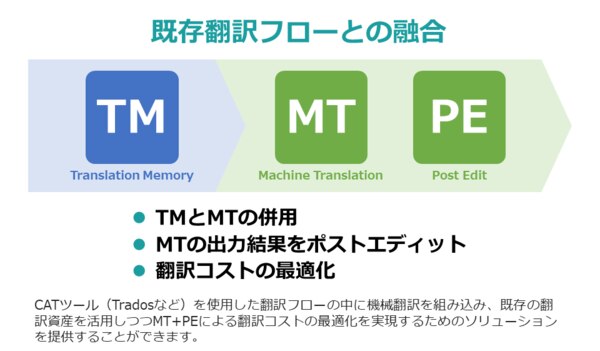
先に述べた翻訳支援ツールでは、プラグインやAPIですでに主要な機械翻訳エンジンとの連携ができるようになっています(有償のものもあります)。
こうした連携によって、大きく翻訳作業の工数を削減できることがあるのは確かですが、それでも文書翻訳が完全に「自動翻訳」と呼ばれないのは、文書の種類や分野によっては、まだまだ人の介在が必要であるからではないでしょうか。プレスリリースなど、公開することが前提となっている文書の目的によっては、最初からプロの翻訳者による翻訳が依頼されるケースの方がまだまだ多いのです。
今後はもっと人間が機械のメリットを活用することができる時代がやってくると思います。しかし、すべての文書を「自動翻訳」できるにはまだまだ時間がかかりそうです。「自動翻訳」と呼ぼうが「機械翻訳」と呼ぼうが、時と場合によって要求品質は変わることをしっかり理解して、適切に選択できるようにしておく必要がありそうですね。
フィードバックフォーム
当サイトで検証してほしいこと、記事にしてほしい題材などありましたら、
下のフィードバックフォームよりお気軽にお知らせ下さい!
例えば・・・
CATツールを自社に導入したいが、どれを選べばいいか分からないのでオススメを教えてほしい。
機械翻訳と人手翻訳、どちらを選ぶべきかわからない。
翻訳会社に提案された「用語集作成」ってどんなメリットがあるの?
ご意見ご要望をお待ちしております!
下のフィードバックフォームよりお気軽にお知らせ下さい!
例えば・・・
CATツールを自社に導入したいが、どれを選べばいいか分からないのでオススメを教えてほしい。
機械翻訳と人手翻訳、どちらを選ぶべきかわからない。
翻訳会社に提案された「用語集作成」ってどんなメリットがあるの?
ご意見ご要望をお待ちしております!
新着記事一覧



