


自社専用のカスタマイズエンジンを導入!
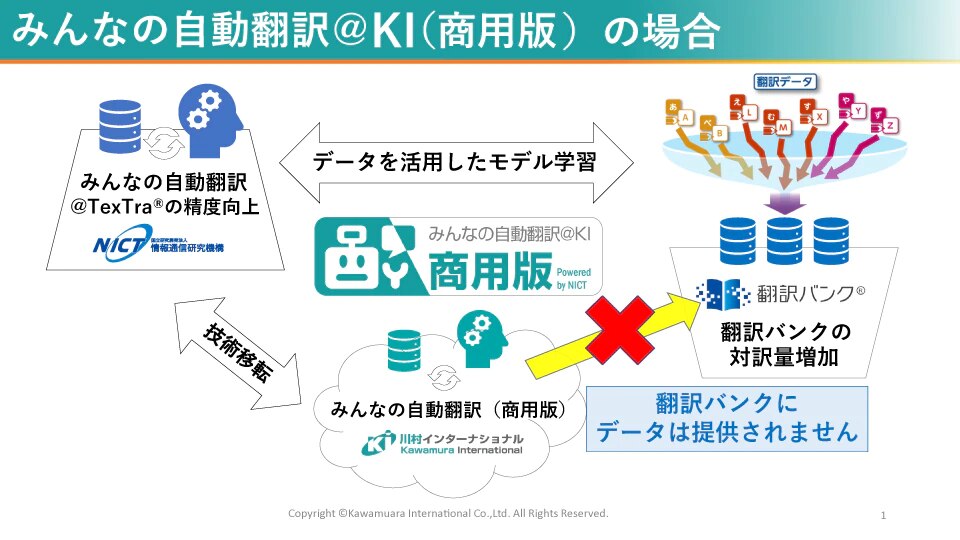
「みんなの自動翻訳@KI(商用版)」は、「翻訳バンク®」を活用して構築した汎用的な自動翻訳エンジンですが、このエンジンは、利用者の許可なくデータが「翻訳バンク®」に提供されることは決してございません。
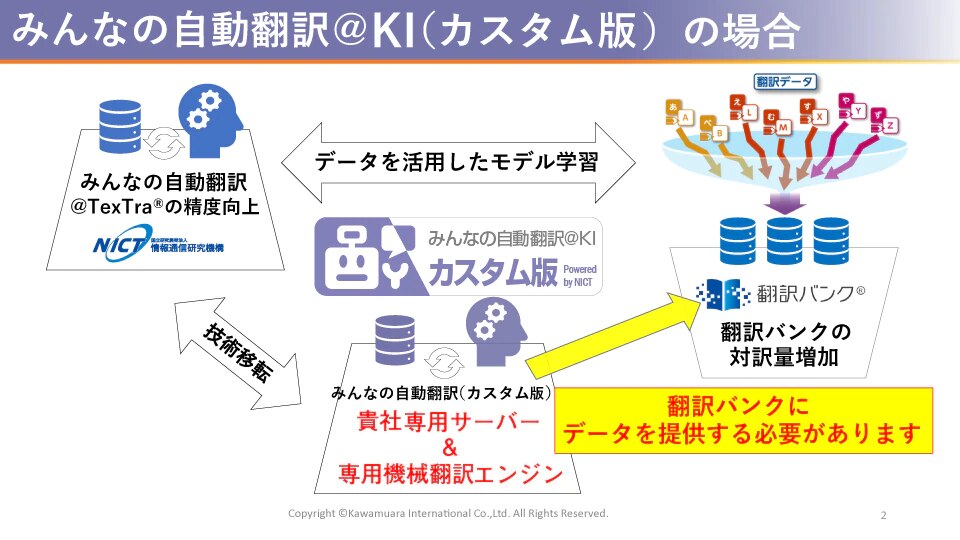
一方、「みんなの自動翻訳@KI(カスタム版)」は「翻訳バンク®」にデータを提供して、オール・ジャパンの枠組みに協力することを前提に、自社向けの自動翻訳エンジンを構築できるテイラーメイドのサービスです。
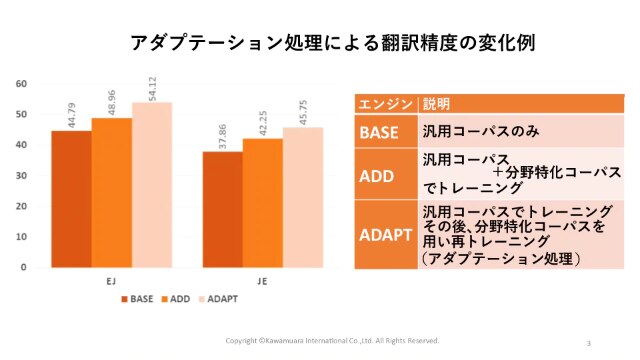
汎用的なデータと一緒に、自社固有の対訳データを機械学習させることで、機械翻訳の精度を向上させる仕組みを「アダプテーション」と呼びます。特定のドメイン(分野)の対訳データを元に、アダプテーション前と後の翻訳精度を比較したグラフが以下の通りです。
「翻訳バンク®」というオールジャパン体制で構築した対訳データと、特定分野に特化した対訳データを合わせて活用することで、「自社用にカスタマイズされた機械翻訳エンジンを活用したい」というニーズに応えることができます。
みんなの自動翻訳@KI(カスタム版)は、国立研究開発法人情報通信研究機構 (NICT) が開発したメイド・イン・ジャパンの自動翻訳エンジンを活用し、自社向けにカスタマイズしたエンジンです。御社のためだけに特別にカスタマイズしたエンジンですので、アクセスできるのも御社に限定されています。
ご要望に応じて、固定IPやプライベートクラウド上での展開も可能です。

契約を締結した後、カスタマイズされた機械翻訳エンジンをご指定の場所に移管します。
※この時点では、「翻訳バンク®」に対訳データが移管されます。
「みんなの自動翻訳@KI(商用版)」の
バージョン7.0をリリースしました
- 汎用エンジンにて4言語を追加 日・英⇔フィリピン語、クメール語、モンゴル語、ネパール語
- PDF/Word/Excel/PowerPoint形式など ファイル翻訳機能を追加
- 文書の文字認識、OCR機能を追加(Word/Excel/PowerPoint形式での出力が可能)
ファイル翻訳ファイル対応形式:PDF、Word、Excel、PowerPoint、txt、htm、html、jpg、jpeg、png、tif、tiff、bmp
OCR原文対応言語:日本語・英語・中国語(簡体字・繁体字)・ドイツ語・スペイン語・フランス語・インドネシア語・イタリア語・韓国語・ポルトガル語・ロシア語
導入の流れ

ヒアリング・デモ
※この時点では、「翻訳バンク®」に対訳データが移管することはありません。

トライアル

申込み・導入準備

アフターサポート

国立研究開発法人情報通信研究機構 (NICT) の自動翻訳エンジン「みんなの自動翻訳@TexTra®」は、特許・マニュアルなどの長文翻訳を得意とし、特許庁などと研究の連携も行ってきた高精度の自動翻訳エンジンです。一方で、用途が非商用利用に限定されているため民間の企業内での活用が限定的になっていました。
そんな中 2020 年までに多言語音声翻訳技術の社会実装を目指すグローバルコミューニケーション計画のもとで研究開発に取り組む NICT は、総務省と共に「翻訳バンク®」の運用を開始しました。
「翻訳バンク®」は、2017年9月に総務省およびNICTが開始した、オール・ジャパン体制で翻訳データを集積する枠組みです。自動翻訳技術の性能向上には、翻訳アルゴリズムの改良のみならず、翻訳データの質と量の確保が重要です。翻訳バンク®では翻訳データを集積して自動翻訳技術に活用することで、自動翻訳技術で対応できる分野を広げるとともに、さらなる高精度化を実現します。
詳細は、NICTによるプレスリリースをご覧ください。
『翻訳バンク®』の運用開始
-自動翻訳システムのさらなる高精度化に向けて、様々な分野の翻訳データを集積-
https://www.nict.go.jp/press/2017/09/08-1.html
